搜索到
78
篇与
Elysian
的结果
-
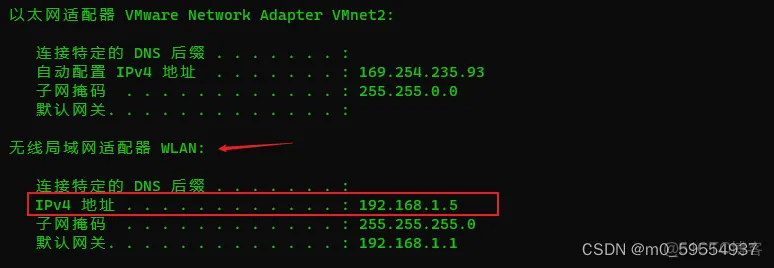
 python windows 微信小程序抓包(转载) APP、小程序、公众号抓包一、APP抓包(一)BurpSuite抓取手机HTTP数据包1、配置代理IP与端口2、测试(二)BurpSuite抓取手机HTTPS数据包1、安装证书2、测试(三)抓不到包?1、原因2、解决思路3、解决过程二、抓取PC端第三方软件数据包流程演示:1、安装证书2、搭建配置Proxifier3、测试三、BurpSuite抓取微信小程序/公众号数据包流程演示:1、安装证书2、Proxifier搭建3、测试一、APP抓包(一)BurpSuite抓取手机HTTP数据包思路:本地主机作为手机的代理服务器,手机APP发送的数据包会直接发给代理服务器,再由代理服务器进行转发。准备工作:手机与本地主机连上同一wifi1、配置代理IP与端口查看主机IP可以在主机使用win+R调出运行框,输入命令cmd进入命令提示符界面,输入ipconfig查看IP:查看手机IP是否正常配置测试连通性在手机上设置代理:在BurpSuite设置拦截经过本地主机的数据包:打开BurpSuite依次点击:Proxy - Options - Add 添加一个监听IP与端口(端口和IP与手机端添加的代理一致)设置好了后,在“Proxy - Intercept 下开启“Intercept is on”就可以对安卓APP的网络数据进行抓包了2、测试手机端随便打开一个app,就会发现数据已经抓到,可以在HTTP history查看(二)BurpSuite抓取手机HTTPS数据包抓取HTTPS包需要导入Burp的证书。特别注意:一个Burp对应一个证书,就是用哪个Burp抓包就导出哪个的证书,并将该证书在手机上安装。1、安装证书有两种方法导出证书:一是直接在BurpSuite导出证书,二是手机端直接访问代理服务器的IP加端口方法一:依次点击 Proxy - Options 选中代理项,点击importexport CA选择第一个,然后点击Next选择保存CA证书的路径,注意文件后缀命名为.cer,因为手机只能安装.cer的证书类型,默认的der格式是不能被识别安装的。方法二:手机访问代理服务器192.168.1.5:8888,点击CA Certificate 进行证书的下载在手机端下载完证书后,依次点击 设置 - 安全 - 从SD卡安装找到证书下载的位置点击进行安装安装完成后可以在 设置 - 安全 - 信任的凭据 看到。2、测试随便打开一个APP或者用HTTPS协议访问任意网站成功抓取到数据包(三)抓不到包? 参考文档1、原因一般情况下手机在安装了BurpSuite的伪证书后,是可以抓大部分APP数据包的,但APP在安卓7.0或更高的系统下,无法抓取数据包,原因是从安卓7.0开始应用只会信任系统预装的CA证书,而不会信任用户安装的CA证书。这种的情况下,一个解决方法就是使用低于7.0版本的安卓系统进行抓包,另一个就是把使用的伪证书安装到系统证书目录中,伪装成系统证书。下面演示将使用的伪证书安装到系统证书目录中的方法和过程。此方法也适用于抓取微信小程序的数据包。2、解决思路1 使用openssl将der证书转为pem证书,生成pem证书的hash,生成要使用的证书。2 使用adb调试功能,将证书放到系统证书目录中。3、解决过程在安卓7.0或者更高的系统下,如果是只把burp证书装到了用户证书中,APP打开后无法正常使用如下,APP加载不出来在手机端导出证书(方法和前面一样)打开kali终端,依次执行以下命令:将导出的证书转pem证书:penssl x509 -inform der -in burp.der -out burp.pem生成pem证书的hash:openssl x509 -inform PEM -subject_hash_old -in burp.pem重命名/复制证书: (将证书文件重命名为“Hash值.0”,如下)cp burp.pem 9a5ba575.0之后将证书文件导出,然后上传到手机端的 /system/security/cacerts/ 目录下赋权:长按文件点击属性,下滑,点击权限,给证书文件644权限这样就可以正常抓包,正常使用APP内的内容二、抓取PC端第三方软件数据包PC客户端的第三方软件一般不支持代理,除了个别会在软件内设置有代理功能,如百度网盘所以要使用Proxifier工具,用于解决代理问题。关于ProxifierProxifier是一款功能非常强大的socks5客户端,可以让不支持通过代理服务器工作的网络程序能通过HTTPS或SOCKS代理或代理链。由于一般的C/S客户端不能设置代理,所以我们FIddler检测不到数据,我们可以通过Proxifer来实现把所有的请求抓发给Fiddler,这样我们就可以在Fiddler分析客户端请求。思路:使用proxifier添加一台代理服务器,这里是本地主机作为代理服务器,数据包会先经过本地主机,然后使用BurpSuite监听或拦截经过主机的数据。流程演示:1、安装证书首先跟前面手机APP抓包一样,导出证书到本地主机,将导出的证书在本地主机进行安装。一路点击下一步到结束,将证书成功安装。2、搭建配置Proxifier①为proxifier添加代理服务器打开proxifier,点击 配置文件 - 配置代理服务器添加代理服务器②打开任务管理器,选择客户端进程,找到所在程序目录复制该程序的路径③配置代理规则点击 选择配置文件 - 配置代理规则将默认规则勾选为Direct,然后点击添加Direct表示数据包直接通过,也可以设置代理,走代理服务器点击浏览,找到复制的路径所在的目录,选择程序最后选择代理拦截④启动代理支持依次点击 高级 - HTTP代理服务器勾选 启用HTTP代理服务器支持 功能重新勾选BurpSuite代理选项,就可以抓包了3、测试随便点击播放音乐成功抓包三、BurpSuite抓取微信小程序/公众号数据包 参考文档:抓取微信小程序/公众号的包需要抓取指定程序的包,可以在PC端登录微信,这样方便些,在PC端操作就要使用Proxifier工具,用于解决代理问题。下面以小程序抓包作为示例流程演示:1、安装证书首先跟前面手机APP抓包一样,导出证书到本地主机,因为这次是微信小程序抓包,可以直接在本地主机登录微信进行抓包。将导出的证书在本地主机进行安装一路点击下一步到结束,将证书成功安装。2、Proxifier搭建①添加代理服务器打开proxifier,点击 配置文件 - 配置代理服务器添加代理服务器②配置代理规则点击 选择配置文件 - 配置代理规则将默认规则勾选为Direct默认规则勾选为Direct是为了不影响除测试程序外的其它程序的正常上网。③打开任务管理器,选择小程序进程,找到所在程序目录复制路径打开Proxifier添加代理规则,将微信的应用添加上,设置走刚刚添加的代理服务器3、测试打开任意一个小程序,成功抓取到数据包本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。python windows 微信小程序抓包https://blog.51cto.com/u_16213619/13989161
python windows 微信小程序抓包(转载) APP、小程序、公众号抓包一、APP抓包(一)BurpSuite抓取手机HTTP数据包1、配置代理IP与端口2、测试(二)BurpSuite抓取手机HTTPS数据包1、安装证书2、测试(三)抓不到包?1、原因2、解决思路3、解决过程二、抓取PC端第三方软件数据包流程演示:1、安装证书2、搭建配置Proxifier3、测试三、BurpSuite抓取微信小程序/公众号数据包流程演示:1、安装证书2、Proxifier搭建3、测试一、APP抓包(一)BurpSuite抓取手机HTTP数据包思路:本地主机作为手机的代理服务器,手机APP发送的数据包会直接发给代理服务器,再由代理服务器进行转发。准备工作:手机与本地主机连上同一wifi1、配置代理IP与端口查看主机IP可以在主机使用win+R调出运行框,输入命令cmd进入命令提示符界面,输入ipconfig查看IP:查看手机IP是否正常配置测试连通性在手机上设置代理:在BurpSuite设置拦截经过本地主机的数据包:打开BurpSuite依次点击:Proxy - Options - Add 添加一个监听IP与端口(端口和IP与手机端添加的代理一致)设置好了后,在“Proxy - Intercept 下开启“Intercept is on”就可以对安卓APP的网络数据进行抓包了2、测试手机端随便打开一个app,就会发现数据已经抓到,可以在HTTP history查看(二)BurpSuite抓取手机HTTPS数据包抓取HTTPS包需要导入Burp的证书。特别注意:一个Burp对应一个证书,就是用哪个Burp抓包就导出哪个的证书,并将该证书在手机上安装。1、安装证书有两种方法导出证书:一是直接在BurpSuite导出证书,二是手机端直接访问代理服务器的IP加端口方法一:依次点击 Proxy - Options 选中代理项,点击importexport CA选择第一个,然后点击Next选择保存CA证书的路径,注意文件后缀命名为.cer,因为手机只能安装.cer的证书类型,默认的der格式是不能被识别安装的。方法二:手机访问代理服务器192.168.1.5:8888,点击CA Certificate 进行证书的下载在手机端下载完证书后,依次点击 设置 - 安全 - 从SD卡安装找到证书下载的位置点击进行安装安装完成后可以在 设置 - 安全 - 信任的凭据 看到。2、测试随便打开一个APP或者用HTTPS协议访问任意网站成功抓取到数据包(三)抓不到包? 参考文档1、原因一般情况下手机在安装了BurpSuite的伪证书后,是可以抓大部分APP数据包的,但APP在安卓7.0或更高的系统下,无法抓取数据包,原因是从安卓7.0开始应用只会信任系统预装的CA证书,而不会信任用户安装的CA证书。这种的情况下,一个解决方法就是使用低于7.0版本的安卓系统进行抓包,另一个就是把使用的伪证书安装到系统证书目录中,伪装成系统证书。下面演示将使用的伪证书安装到系统证书目录中的方法和过程。此方法也适用于抓取微信小程序的数据包。2、解决思路1 使用openssl将der证书转为pem证书,生成pem证书的hash,生成要使用的证书。2 使用adb调试功能,将证书放到系统证书目录中。3、解决过程在安卓7.0或者更高的系统下,如果是只把burp证书装到了用户证书中,APP打开后无法正常使用如下,APP加载不出来在手机端导出证书(方法和前面一样)打开kali终端,依次执行以下命令:将导出的证书转pem证书:penssl x509 -inform der -in burp.der -out burp.pem生成pem证书的hash:openssl x509 -inform PEM -subject_hash_old -in burp.pem重命名/复制证书: (将证书文件重命名为“Hash值.0”,如下)cp burp.pem 9a5ba575.0之后将证书文件导出,然后上传到手机端的 /system/security/cacerts/ 目录下赋权:长按文件点击属性,下滑,点击权限,给证书文件644权限这样就可以正常抓包,正常使用APP内的内容二、抓取PC端第三方软件数据包PC客户端的第三方软件一般不支持代理,除了个别会在软件内设置有代理功能,如百度网盘所以要使用Proxifier工具,用于解决代理问题。关于ProxifierProxifier是一款功能非常强大的socks5客户端,可以让不支持通过代理服务器工作的网络程序能通过HTTPS或SOCKS代理或代理链。由于一般的C/S客户端不能设置代理,所以我们FIddler检测不到数据,我们可以通过Proxifer来实现把所有的请求抓发给Fiddler,这样我们就可以在Fiddler分析客户端请求。思路:使用proxifier添加一台代理服务器,这里是本地主机作为代理服务器,数据包会先经过本地主机,然后使用BurpSuite监听或拦截经过主机的数据。流程演示:1、安装证书首先跟前面手机APP抓包一样,导出证书到本地主机,将导出的证书在本地主机进行安装。一路点击下一步到结束,将证书成功安装。2、搭建配置Proxifier①为proxifier添加代理服务器打开proxifier,点击 配置文件 - 配置代理服务器添加代理服务器②打开任务管理器,选择客户端进程,找到所在程序目录复制该程序的路径③配置代理规则点击 选择配置文件 - 配置代理规则将默认规则勾选为Direct,然后点击添加Direct表示数据包直接通过,也可以设置代理,走代理服务器点击浏览,找到复制的路径所在的目录,选择程序最后选择代理拦截④启动代理支持依次点击 高级 - HTTP代理服务器勾选 启用HTTP代理服务器支持 功能重新勾选BurpSuite代理选项,就可以抓包了3、测试随便点击播放音乐成功抓包三、BurpSuite抓取微信小程序/公众号数据包 参考文档:抓取微信小程序/公众号的包需要抓取指定程序的包,可以在PC端登录微信,这样方便些,在PC端操作就要使用Proxifier工具,用于解决代理问题。下面以小程序抓包作为示例流程演示:1、安装证书首先跟前面手机APP抓包一样,导出证书到本地主机,因为这次是微信小程序抓包,可以直接在本地主机登录微信进行抓包。将导出的证书在本地主机进行安装一路点击下一步到结束,将证书成功安装。2、Proxifier搭建①添加代理服务器打开proxifier,点击 配置文件 - 配置代理服务器添加代理服务器②配置代理规则点击 选择配置文件 - 配置代理规则将默认规则勾选为Direct默认规则勾选为Direct是为了不影响除测试程序外的其它程序的正常上网。③打开任务管理器,选择小程序进程,找到所在程序目录复制路径打开Proxifier添加代理规则,将微信的应用添加上,设置走刚刚添加的代理服务器3、测试打开任意一个小程序,成功抓取到数据包本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。python windows 微信小程序抓包https://blog.51cto.com/u_16213619/13989161 -
-
docker搭建open-webui docker-compose.yamlversion: '3' services: open-webui: image: 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/open-webui/open-webui:v0.6.5' restart: always container_name: open-webui volumes: - './data:/app/backend/data' environment: - OFFLINE_MODE=True - HF_ENDPOINT=https://hf-mirror.com - TZ=Asia/Shanghai - USE_OLLAMA_DOCKER=False # 不使用集成 Ollama 容器 ports: - '8080:8080'open-webui具体使用说明和配置内容可以参考下面链接 【2025最新】DeepSeek-R1+Open-WebUI双系统部署全攻略:从Linux到Windows保姆级教程,手把手搭建可视化AI对话平台
-
阿里云+DDNS-GO+宝塔反向代理内网穿透后使用域名无端口访问内网保姆级教程 第1章 需求的简介和应用功能的概述1.1 简介 由于公司没有允许员工使用云服务,同时又需要远程存储家中监控摄像头的数据,笔者决定购买一台NAS设备来解决生活和工作上的问题。在经过多方考虑后,笔者选择了绿联NAS,因为它非常适合初学者,而且自带docker,可扩展性非常高。但是,想要玩转NAS,必须实现内网穿透。如果不进行内网穿透,那么即使购买了NAS,也无法实现远程访问。由于笔者家里的宽带没有公网IP,所以只能采用DDNS-TO进行内网穿透,但它还是存在一些局限性的,例如连接端口数量上限、带宽容量上限等。此外,如果安装应用程序,还需要在DDNS-TO上添加映射,操作较为繁琐。然而,DDNS-TO也有其优点,例如支持HTTPS方式访问,安装配置简单等。为了替代DDNS-TO的缺陷并保留其优点,笔者通过学习,决定使用 DDNS-GO、阿里云、NginxWebUI、cloudflare组合来实现我的需求。1.2 应用功能概述为了替换DDNS-TO的缺点,笔者决定使用DDNS-GO、阿里云、NginxWebUI下面简单概述这些工具各自的功能和解决的问题。1.2.1 阿里云阿里云提供了域名服务,可以申请短期免费或长期付费的域名,并且没有连接端口数量上限和带宽容量上限的限制。此外,用户还可以进行个性化自定义,非常方便。同时,阿里云还提供了API密钥(Accesskey id和Accesskey Secret)以及家庭局域网动态公网IP地址与域名的绑定,在NAS上安装应用程序时,只需要记住应用映射的域名即可。1.2.2 DDNS-GODDNS-GO是一款非常实用的内网穿透工具,仅限于无固定IPV4地址和IPV6地址,但有真实动态IPV4地址的内网环境。如果用户拥有固定IPV6或固定IPV4中的其中一种公网IP地址,则不必关注该工具,也无需安装。需要注意的是,获取公网IP需要将光猫改成桥接,而光猫如何改桥接及光猫开通IPV6因运营商而异,用户需要自行百度或咨询运营商的工作人员。使用DDNS-GO做内网穿透前,必须要确定公网IPV4地址是否真实有效,否则可能会出现问题。1.2.3 NginxWebUINginxWebUI是一款管理Nginx服务器的Web界面,支持在Nginx中添加和删除域名、配置文件等操作。它可以通过docker安装在绿联NAS上,方便用户进行管理。2.访问你的路由器,找到上网设置,查看你路由器上的公网IP 正常路由器地址:192.168.2.1 192.168.0.1 192.168.31.13.如果以上两个公网IP是一致的,这意味着公网动态IPV4地址是真实有效的。如果不一致,则说明当前没有公网IP地址。若出现后者,建议直接联系宽带运营商开通动态IPV4或提供固定IPV6地址。如果这些方式都无法满足需求,可以考虑更换宽带运营商或使用其他内网穿透方式(例如DDNS-TO)。1.2.3 NginxWebUINginxWebUI是一款非常实用的工具,它可以实现反向代理,从而访问内网NAS上安装的应用程序,在访问内网应用之前,需要先经过Nginx进行代理。此外,NginxWebUI还支持根据域名生成免费的SSL证书,并将http请求转化为https请求。1.2.4 cloudflarecloudflare是一个全球性的CDN网络,提供了很多有用的功能,例如网站加速、防火墙等。通过将自己的域名指向cloudflare,用户可以隐藏NAS真实的IP地址,避免黑客攻击。同时,它还能够转发URL路径重定向,使用户只需使用域名访问而不用带上特定的端口号。第2章 各应用的安装配置2.1 阿里云的注册和域名申请2.1.1 注册为了使用阿里云提供的服务,首先需要注册一个账户。如果您已经拥有阿里云账户,则可以直接跳过这一步。在访问阿里云的官方网站后,点击“登录/注册”,按照指示填写信息并完成注册。2.1.2 域名申请在注册成功之后,可以开始申请域名。这里推荐申请一个.cn或.com的域名,因为这两种域名是最通用的。在阿里云的控制台中,选择“域名”选项卡,然后按照页面上的提示申请域名。当您完成付款后,就可以获得您自己的域名了。2.2 DDNS-GO的配置2.2.1 安装DDNS-GODDNS-GO可以通过绿联NAS上的docker进行安装,只需在终端中输入相应的命令即可。2.2.2 DDNS-GO的配置在安装完成后,需要进行一些配置工作。首先,在阿里云的控制台中创建一对API密钥,并将其保存起来。然后,在DDNS-GO的设置中输入相关信息,例如域名、密钥等。最后,启动DDNS-GO,测试与阿里云的连接是否正常。阿里云访问地址:https://www.aliyun.com,支持多种注册方式,自行注册。2.1.2 申请阿里云 API 的密钥A.注册并登录阿里云后,双击网站首页右上角的“控制台“并进入。B.设置权限模式C.在”AccessKey管理”界面创建AccessKeyD.AccessKey ID和AccessKey Secret申请成功后复制到本地保存,后面安装完DDNS-GO后做动态域名绑定时要用到2.1.3 注册域名 (有域名的可略过,没域名的买个最便宜的后缀即可)A.在阿里云首页双击搜索图标,选择域名搜索使用域名需要进行实名认证,具体操作请根据网站提示完成。注册时选择个人使用即可,不需要进行备案。2.1.4 添加二级域名在申请一级域名之后,我们需要再添加一个前缀来变成二级域名。例如,如果一级域名是“huixx.com”,那么可以加上前缀“www”来变成二级域名“www.huixx.cc”。理论上,只要前缀不同,我们就可以拥有无数个二级域名。A. 申请一级域名后,需要在阿里云的控制台中添加相应的记录来创建二级域名。2.2 DDNS-GO的安装和配置2.2.1 安装配置1.wget https://github.com/jeessy2/ddns-go/releases/download/v6.6.2/ddns-go_6.6.2_linux_x86_64.tar.gz2.tar-zxvf ddns-go_6.6.2_linux_x86_64.tar.gz3.cd ddns-go_6.6.2_linux_x86_644.sudo ./ddns-go -s install启动ddns-gosystemctl start ddns-go设置开机自启systemctl enable ddns-go查看运行状态systemctl status ddns-go.service9.通过宿主机访问浏览器页面进行配置(如果是gui的安装可以直接浏览器访问127.0.0.1:9876)2.2.1 配置DDNS-go (安装机器:192.168.2.x:9876)2.2.3 验证内网穿透A.登录阿里云上查看二级域名的记录值(绑定的动态公网IP)是否正确,是否正常B.将pve的8006端口在路由器里做端口映射C.在公网上用浏览器中域名+端口(例如http://www.huixx.cc:8006)的方式访问pve。如果能正常访问则说明内网穿透鼓捣成功了。为了验证的严谨性,测试终端连接的公网和pve接入的公网的不要不要在同一个局域网内通过以上步骤的设置基本解决了pve的内网穿透需求。通过在路由器中映射不同的端口,来开通NAS上安装应用的公网访问限制。但仍然有些小瑕疵,例如:1.使用的是http协议明文访问,未加密。终极目标是使用https协议加密访问。2.访问时需要带端口,不像正规的网站,并且不同的应用要映射不同的端口,不便于记忆。目标是只使用域名访问,例如:“https://www.huixx.com”。3.做端口映射还要登录路由器。目标是使用软件程序代替路由器来做映射。要解决以上问题,需要继续执行后面的工作。原文链接:https://blog.csdn.net/samly6/article/details/139878859
-
PaddleOCR Linux-Centos7.6安装与部署 1. 运行环境准备本人环境为阿里云服务器centos 7.6(全新镜像系统)从0开始部署PaddleOCR1.1 参考资料PaddleOCR 运行环境准备 PaddleOCR 快速开始 手把手0基础Centos下安装与部署paddleOcr 教程 PaddleOCR基于PaddleHub Serving的服务部署(docker环境) 新手Docker安装PaddleOCR快速指导(非长期有效具体看更新时间) (ziyoukaifa.com) PaddleOCR Linux-Centos7.6安装与部署1.2 PaddleOCR的环境推荐环境:PaddlePaddle >= 2.1.2 Python 3.7 CUDA10.1 / CUDA10.2 CUDNN 7.62. centos下准备好docker工具可以自己选择一个稳定的版本安装,或者不指定版本,直接安装最新版本2.1 备份之前的yum源文件cd /etc/yum.repos.d/ mv CentOS-Base.repo CentOS-Base.repo_bak2.2 更换yum源为阿里云wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo2.3 清除缓存并生成新的缓存yum.repos.d]# yum clean all yum makecache2.4测试发现还是报错yum list docker-ce --showduplicates | sort -r Error: No matching Packages to list \* updates: mirrors.bfsu.edu.cn Loading mirror speeds from cached hostfile Loaded plugins: fastestmirror, langpacks \* extras: mirrors.bfsu.edu.cn \* base: mirrors.bfsu.edu.cn2.5 添加仓库yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo2.6 IF ERROR: yum-config-manager: command not foundyum -y install yum-utils yum clean all yum makecache2.7 再次测试,发现OKyum list docker-ce --showduplicates | sort -r //显示如下 docker-ce.x86\_64 3:20.10.0-3.el7 docker-ce-stable2.8 yum install docker-ce接下来就是yum来安装docker完成yum install docker-ce2.9 启动docker服务service docker start2.10 查看docker版本,检查docker是否安装成功docker --version #显示如下 Docker version 24.0.2, build cb74dfc2.11 配置docker服务开机自启动systemctl enable docker3.Docker环境配置切换到工作目录下mkdir /home/Projects cd /home/Projects首次运行需创建一个docker容器,再次运行时不需要运行当前命令创建一个名字为ppocr的docker容器,并将当前目录映射到容器的/paddle目录下3.1镜像下载接下来docker就会自动开始下载镜像了,然后就是漫长的下载等待,大概下载时间会有10分钟左右在CPU环境下使用docker,使用docker而不是nvidia-docker创建dockersudo docker run --name ppocr -v \$PWD:/paddle --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash下载完毕后,会自动进入到镜像内部的shell里,进入下面这样的界面中。我们先直接输入exit退出 exit3.2查看docker中的运行进程docker ps3.3启动ppocr这个容器docker start ppocr3.4进入ppocr容器sudo docker container exec -it ppocr /bin/bash3.5 检查docker内的python3以及pip3版本python>=3.7.04.安装最新PaddlePaddle(2.4.2)python3 -m pip install paddlepaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple4.1 安装PaddleOCR whl包pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本这个包一般下载得会比较久4.2 包版本依赖不兼容报错问题Paddlepaddle 2.4.2需要protobuf<=3.20.0,>=3.1.0,但你有protobuf 4.23.2,这是不兼容的。4.2.1 重新换一个 protobuf 版本/home pip uninstall protobuf /home pip install protobuf==3.20.0OK没有其它包不兼容了,如果还存在包兼容问题根据错误提示升级或降级对应包即可4.3 clone PaddleOCR仓库代码cd /home git clone https://github.com/PaddlePaddle/PaddleOC #【推荐】 #如果无法访问github 的小伙伴们也可以通过gitee仓库里面将源码下载下来: git clone https://gitee.com/paddlepaddle/PaddleOCR5. 安装paddlehub(2.2.0)cd /home/PaddleOCR安装paddlehubpip3 install paddlehub==2.2.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple5.0.1 jupyter-console 包依赖冲突错误:pip的依赖解析器目前没有考虑所有已安装的包。这种行为是下列依赖冲突的根源。Jupyter-console 6.4.0需要prompt-toolkit!=3.0.0,!=3.0.1,❤️.1.0,>=2.0.0,但您有不兼容的prompt-toolkit 1.0.185.0.2 更换 Jupyter-console 版本卸载Jupyter-consolepip3 uninstall jupyter-console pip3 install jupyter-console==4.0.25.1 安装requirements.txt 依赖pip install -r requirements.txt -i https://pypi.douban.com/simple #如果提示albumentations包版本不存在则将requirements.txt中的albumentations包版本替换成 #albumentations==1.3.16. 下载轻量的推理模型安装服务模块前,需要准备推理模型并放到正确路径。我们将使用的是最新PP-OCRv3模型,默认模型路径为:**检测模型:./inference/ch_PP-OCRv3_det_infer/识别模型:./inference/ch_PP-OCRv3_rec_infer/方向分类器:./inference/ch_ppocr_mobile_v2.0_cls_infer/进入/home/PaddleOCR/deploy/hubserving/ocr_system下cd /home/PaddleOCR/deploy/hubserving/ocr_system # 下载并解压检测模型 wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar && tar -xf ch_PP-OCRv3_det_infer.tar && rm -rf ch_PP-OCRv3_det_infer.tar # 下载并解压识别模型 wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar && tar -xf ch_PP-OCRv3_rec_infer.tar && rm -rf ch_PP-OCRv3_rec_infer.tar # 下载并解压方向分类器 wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar -xf ch_ppocr_mobile_v2.0_cls_infer.tar && rm -rf ch_ppocr_mobile_v2.0_cls_infer.tar全部下载解压完后输ls查看目录确认6.1 修改模型路径修改三个dir,注意要绝对路径,以及rec_imgage_shape最新PP-OCR3为3.48.3206.2 单张图片识别测试回到 cd /home/paddleOCR 目录下图片测试用官方自带的图片来测试识别,官方自带图片目录为 /home/PaddleOCR/doc/imgspython3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system/ch_PP-OCRv3_det_infer/" --rec_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system//ch_PP-OCRv3_rec_infer/" --cls_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls true --use_gpu false7. PaddleHub Server 服务部署这种部署形式也是官方推荐的部署方式之一。7.1 安装服务模块PaddleOCR提供3种服务模块,根据需要安装所需模块安装检测+识别串联服务模块即可 cd /home/PaddleOCR 安装检测服务模块: hub install deploy/hubserving/ocr_det/ 或,安装分类服务模块: hub install deploy/hubserving/ocr_cls/ 或,安装识别服务模块: hub install deploy/hubserving/ocr_rec/ 或,安装检测+识别串联服务模块: hub install deploy/hubserving/ocr_system/7.2 自定义修改服务模块(后续,现可跳过)如果需要修改服务逻辑,你一般需要操作以下步骤(以修改ocr_system为例):7.2.1 停止服务hub serving stop --port/-p XXXX7.2.2 修改参数到相应的module.py和params.py等文件中根据实际需求修改代码。例如,如果需要替换部署服务所用模型,则需要到 params.py 中修改模型路径参数det_model_dir和rec_model_dir,如果需要关闭文本方向分类器,则将参数use_angle_cls置为False,当然,同时可能还需要修改其他相关参数,请根据实际情况修改调试。 强烈建议修改后先直接运行module.py调试,能正确运行预测后再启动服务测试。7.2.3 卸载旧服务包hub uninstall ocr_system7.2.4 安装修改后的新服务包hub install deploy/hubserving/ocr_system/7.2.5 重新启动服务hub serving start -m ocr_system7.3 hub 配置文件init_args中的可配参数与module.py中的_initialize函数接口一致。其中,当use_gpu为true时,表示使用GPU启动服务。predict_args中的可配参数与module.py中的predict函数接口一致。注意:使用配置文件启动服务时,其他参数会被忽略。如果使用GPU预测(即,use_gpu置为true),则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,如:export CUDA_VISIBLE_DEVICES=0,否则不用设置。use_gpu不可与use_multiprocess同时为true7.4 启动 hub 服务命令hub serving start -c config.json成功会出现以下说明,后续测试记得将8868端口放开8. 部署 web 服务程序8.1 安装flask,flask-cors下面使用flask 部署web框架cd /home/PaddleOCR/tools pip3 install flask安装flask-corspip3 install flask-cors8.2 新建web服务程序在 /home/PaddleOCR/tools 目录下新建一个新的py文件,文件名为testmyocr.py 并且给权限为 775testmyocr.py的内容如下:# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. import os import sys __dir__ = os.path.dirname(os.path.abspath(__file__)) sys.path.append(__dir__) sys.path.append(os.path.abspath(os.path.join(__dir__, '..'))) from ppocr.utils.logging import get_logger logger = get_logger() import cv2 import numpy as np import time from PIL import Image from ppocr.utils.utility import get_image_file_list from tools.infer.utility import draw_ocr, draw_boxes import requests import json import base64 from flask import Flask,request from flask_cors import CORS import requests app = Flask(__name__) CORS(app) # 解决跨域问题 def cv2_to_base64(image): return base64.b64encode(image).decode('utf8') def draw_server_result(image_file, res): img = cv2.imread(image_file) image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) if len(res) == 0: return np.array(image) keys = res[0].keys() if 'text_region' not in keys: # for ocr_rec, draw function is invalid logger.info("draw function is invalid for ocr_rec!") return None elif 'text' not in keys: # for ocr_det logger.info("draw text boxes only!") boxes = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) boxes = np.array(boxes) draw_img = draw_boxes(image, boxes) return draw_img else: # for ocr_system logger.info("draw boxes and texts!") boxes = [] texts = [] scores = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) texts.append(res[dno]['text']) scores.append(res[dno]['confidence']) boxes = np.array(boxes) scores = np.array(scores) draw_img = draw_ocr( image, boxes, texts, scores, draw_txt=True, drop_score=0.5) return draw_img @app.route("/test") def test(): return 'Hello World!' @app.route("/myocr", methods=["POST"] ) def myocr(): # 输入参数 image_file = request.files['file'] basepath = os.path.dirname(__file__) logger.info("{} basepath".format(basepath)) savepath = os.path.join(basepath, image_file.filename) image_file.save(savepath) img = open(savepath, 'rb').read() if img is None: logger.info("error in loading image:{}".format(image_file)) # 转为 base64 data = {'images': [cv2_to_base64(img)]} # 发送请求 url = "http://127.0.0.1:8868/predict/ocr_system" headers = {"Content-type": "application/json"} r = requests.post(url=url, headers=headers, data=json.dumps(data)) # 返回结果 res = r.json()["results"][0] logger.info(res) return json.dumps(res) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000) 8.3 启动web服务cd /home/PaddleOCR/tools 目录切换到tools下 python3 testmyocr.py & 启动web服务,启动成功会出现如下说明9. Postman工具调用测试**使用postman向 5000端口去发起请求,可以看到服务正常返回识别的结果其他方式:https://github.com/velviagris/PaddleOCRFastAPI/blob/master/README_CN.md