搜索到
78
篇与
Elysian
的结果
-
 解决 cURL error 60: SSL certificate problem: unable to get local issuer certificate 异常抛出 cURL error 60: SSL certificate problem: unable to get local issuer certificate (see https://curl.haxx.se/libcurl/c/libcurl-errors.html)报错原因:因为没有配置信任的服务器HTTPS验证。默认情况下,cURL被设为不信任任何CAs,因此浏览器无法通过HTTPs访问你服务器。 解决办法下载证书 ,下载最新的证书就;下载后放入PHP扩展文件中,一般放在ext目录中;修改php.ini文件,去掉注释、加上路径 openssl.cafile = "下载的证书文件完整路径" curl.cainfo = "下载的证书文件完整路径" ;重启环境生效;
解决 cURL error 60: SSL certificate problem: unable to get local issuer certificate 异常抛出 cURL error 60: SSL certificate problem: unable to get local issuer certificate (see https://curl.haxx.se/libcurl/c/libcurl-errors.html)报错原因:因为没有配置信任的服务器HTTPS验证。默认情况下,cURL被设为不信任任何CAs,因此浏览器无法通过HTTPs访问你服务器。 解决办法下载证书 ,下载最新的证书就;下载后放入PHP扩展文件中,一般放在ext目录中;修改php.ini文件,去掉注释、加上路径 openssl.cafile = "下载的证书文件完整路径" curl.cainfo = "下载的证书文件完整路径" ;重启环境生效; -
向ChatGPT提问要素 向ChatGPT提问要素https://chat1.aichatos.com/① 语言简洁明了,指令清晰以李白的风格写一首古诗以李白的风格写一首古诗,描绘长沙天气多变② 问题聚焦我要买一台车我想买一辆车,预算30万,要国产新能源的③ 同一个话题内容尽量相关、换话题要建立新对话(清除上文感染)④ 给GPT一个身份你是一个管理者,马上到月底了,你们团队的月计划还没完成,你怎么办你是一个培训讲师,请帮我向大家介绍一下ChatGPT我希望你担任前端开发人员。您应该将文件合并到单个 index.html 文件中,别无其他。不要写解释。我的第一个请求是“写一个网页程序,黑色背景,模拟星星在夜空闪烁,要很多6px大小的五角星,每个五角星的颜色要随机”⑤ 指定提示信息明确风格用小红书的风格回答这个问题,”豆腐脑是吃甜的还是咸的“,要有emoji表情明确信息品牌名称:欧派家居,品牌成立时间:1994年,品牌定位:一线品牌、中国最有价值品牌500强,请以上述信息写一篇800字的品牌招商文章⑥ 扩散思维扮演一个母老虎和我对话第一步:请问中文语境下,夫妻关系中的母老虎是什么意思?第二步:按GPT描述的母老虎形象复制到对话里面,让GPT扮演第三步:持续带入,引导;比如可以让GPT加上表情、动作等描述让GPT提问,你来回答假装你是一位教中国古诗的老师,我是你的学生,现在课程完毕了,你需要给我出题目让我解答,然后对我的解答做出点评,现在请开始出第一道题让它当工具程序解释器输入php语句,它会给你发送执行结果统计/辨别文本某个词语出现多少次,手机号码筛选等等技巧学习地址https://www.zhihu.com/question/584402332/answer/2956335225https://ai.sph.net/chatgpt-prompthttps://www.aishort.top/StableDiffusionhttp://192.168.1.247:7860/# 羊毛衫玩偶chilloutmixNiPruned.Tw1O.safetensors 基础模型Fantz cartoon monster cat wearing cardigan, Impasto,massurrealism , backlight, voxel art ,psychedelic 提示词bad-picture-chill-75v, text, bad anatomy, crop frame, doubling figures,human 反提示词euler a step 30 系数9 LoRA funnyCreatures 1 参数# 国画美女anything-v4.5 基础模型(masterpiece),best quality,good anatomy, shuimobysim,(1 girl:1), (upper body),(smile),short hair,(hanfu),(ecchi0.5), (trees:0.5), (flowers:0.6) ,(wooden house:0.2),(bamboo forest:0.2),(creek:0.2),(river:0.2) 提示词nsfw,mutated hands, (poorly drawn hands:1.331),(fused fingers:1.61051), (too many fingers:1.61051), bad hands, missing fingers, extra digit, (worst quality:2), (low quality:2), (normal quality:2),bad face,bad hands,bad anatomy, 反提示词DPM++ SDE Karras LoRA Moxin 0.5 Moxin_Shuke 0.8 系数 5 step 28 参数
-
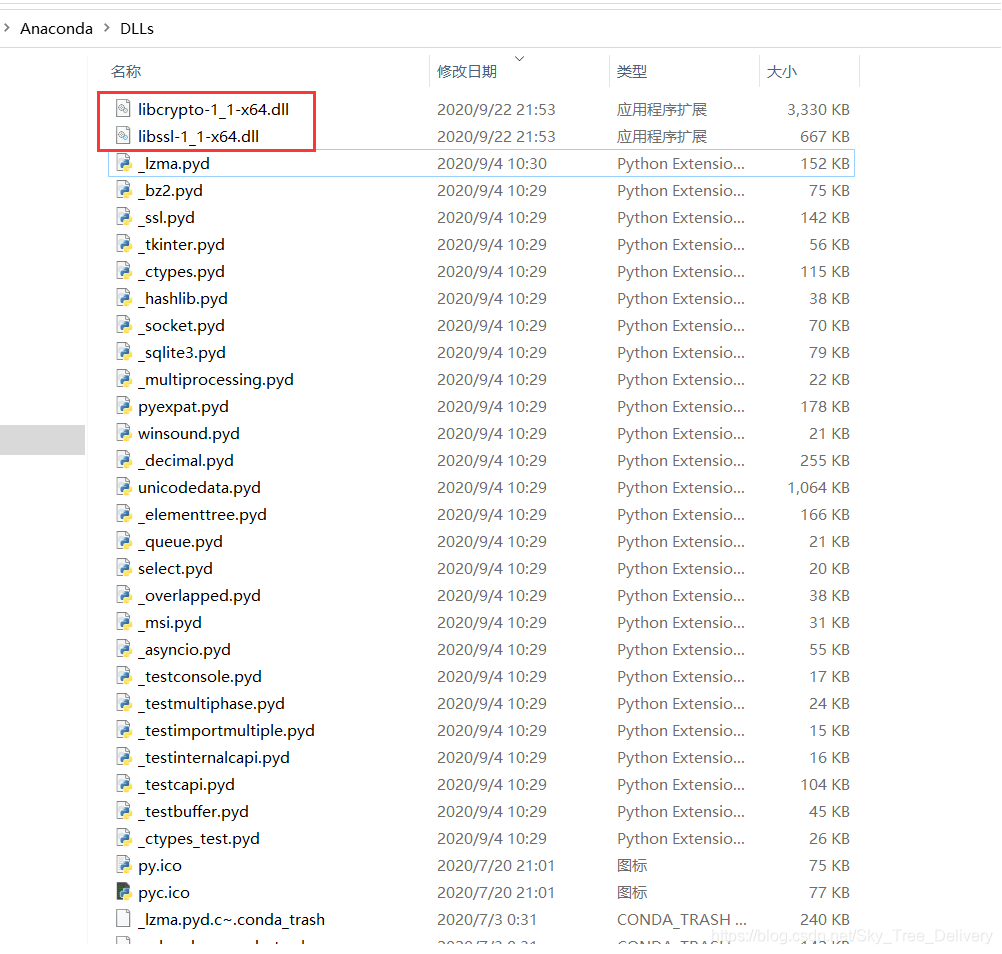
anaconda中SSL错误:Can‘t connect to HTTPS URL because the SSL module is not available 解决方案原文地址 https://github.com/conda/conda/issues/8273大意是:conda找错了openssl的地址,conda在AnacondaDLLs目录下寻找openssl的dll文件,但实际上需要的dll在Anaconda3librarybin目录下。因此只需要将这两个文件复制到 AnacondaDLLs下即可。根据提示复制两个dll到指定目录。D:AnacondaLibrarybin -> D:AnacondaDLLs
-
修改pip install默认安装路径的方法 修改pip install默认安装路径python 模块默认安装路径在C盘,容易造成C盘占满,所以需要修改安装路径查看pip 默认安装位置cmd 输入 python -m site修改pip 默认安装位置cmd 输入 python -m site -help修改site.py内容,如下USER_SITE = "你的其他目录\lib\site-packages" USER_BASE = "你的其他目录\Scripts"增加pip配置文件pip.ini在user目录(一般是C:用户你的系统用户名)下新建pip文件夹,里面新建pip.ini文件,内容如下[global] index-url=https://mirrors.aliyun.com/pypi/simple/ target=D:/Cache/Python/Python38/site-packages修改完后就可以了,测试一下,cmd输入命令 pip install numpy至此pip安装的模块默认路径就修改了pip 安装慢,请使用国内的镜像源pip install mlxtend -i https://pypi.tuna.tsinghua.edu.cn/simple
-
git如何修改其不区分文件大小写(默认忽略大小写)的设置 因为git默认的设置是忽略文件大小写的,这就会有可能导致不同分支拉取下来的同一文件的文件名大小写却不同,从而导致代码中对应的路径找不到而报错,那么这种问题怎么处理呢?很简单,直接使用 git config core.ignorecase false 命令 把git忽略大小写的配置关掉;我们可以使用 git config core.ignorecase 命令来检查当前git配置的是否忽略大小写的配置,默认情况下应该是返回true,表示是忽略大小写的,不区分大小写;当我们执行 git config core.ignorecase false 后 再去 执行 git config core.ignorecase 会发现这时候返回值是 false 代表我们成功关掉了git的忽略大小写配置;PS:在linux系统中,大小写是敏感的,所以配置GIT的时候需要设置一下,再就是设置命令时使用git的命令工具,不要使用cmd