搜索到
6
篇与
python
的结果
-
 PaddleOCR Linux-Centos7.6安装与部署 1. 运行环境准备本人环境为阿里云服务器centos 7.6(全新镜像系统)从0开始部署PaddleOCR1.1 参考资料PaddleOCR 运行环境准备 PaddleOCR 快速开始 手把手0基础Centos下安装与部署paddleOcr 教程 PaddleOCR基于PaddleHub Serving的服务部署(docker环境) 新手Docker安装PaddleOCR快速指导(非长期有效具体看更新时间) (ziyoukaifa.com) PaddleOCR Linux-Centos7.6安装与部署1.2 PaddleOCR的环境推荐环境:PaddlePaddle >= 2.1.2 Python 3.7 CUDA10.1 / CUDA10.2 CUDNN 7.62. centos下准备好docker工具可以自己选择一个稳定的版本安装,或者不指定版本,直接安装最新版本2.1 备份之前的yum源文件cd /etc/yum.repos.d/ mv CentOS-Base.repo CentOS-Base.repo_bak2.2 更换yum源为阿里云wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo2.3 清除缓存并生成新的缓存yum.repos.d]# yum clean all yum makecache2.4测试发现还是报错yum list docker-ce --showduplicates | sort -r Error: No matching Packages to list \* updates: mirrors.bfsu.edu.cn Loading mirror speeds from cached hostfile Loaded plugins: fastestmirror, langpacks \* extras: mirrors.bfsu.edu.cn \* base: mirrors.bfsu.edu.cn2.5 添加仓库yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo2.6 IF ERROR: yum-config-manager: command not foundyum -y install yum-utils yum clean all yum makecache2.7 再次测试,发现OKyum list docker-ce --showduplicates | sort -r //显示如下 docker-ce.x86\_64 3:20.10.0-3.el7 docker-ce-stable2.8 yum install docker-ce接下来就是yum来安装docker完成yum install docker-ce2.9 启动docker服务service docker start2.10 查看docker版本,检查docker是否安装成功docker --version #显示如下 Docker version 24.0.2, build cb74dfc2.11 配置docker服务开机自启动systemctl enable docker3.Docker环境配置切换到工作目录下mkdir /home/Projects cd /home/Projects首次运行需创建一个docker容器,再次运行时不需要运行当前命令创建一个名字为ppocr的docker容器,并将当前目录映射到容器的/paddle目录下3.1镜像下载接下来docker就会自动开始下载镜像了,然后就是漫长的下载等待,大概下载时间会有10分钟左右在CPU环境下使用docker,使用docker而不是nvidia-docker创建dockersudo docker run --name ppocr -v \$PWD:/paddle --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash下载完毕后,会自动进入到镜像内部的shell里,进入下面这样的界面中。我们先直接输入exit退出 exit3.2查看docker中的运行进程docker ps3.3启动ppocr这个容器docker start ppocr3.4进入ppocr容器sudo docker container exec -it ppocr /bin/bash3.5 检查docker内的python3以及pip3版本python>=3.7.04.安装最新PaddlePaddle(2.4.2)python3 -m pip install paddlepaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple4.1 安装PaddleOCR whl包pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本这个包一般下载得会比较久4.2 包版本依赖不兼容报错问题Paddlepaddle 2.4.2需要protobuf<=3.20.0,>=3.1.0,但你有protobuf 4.23.2,这是不兼容的。4.2.1 重新换一个 protobuf 版本/home pip uninstall protobuf /home pip install protobuf==3.20.0OK没有其它包不兼容了,如果还存在包兼容问题根据错误提示升级或降级对应包即可4.3 clone PaddleOCR仓库代码cd /home git clone https://github.com/PaddlePaddle/PaddleOC #【推荐】 #如果无法访问github 的小伙伴们也可以通过gitee仓库里面将源码下载下来: git clone https://gitee.com/paddlepaddle/PaddleOCR5. 安装paddlehub(2.2.0)cd /home/PaddleOCR安装paddlehubpip3 install paddlehub==2.2.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple5.0.1 jupyter-console 包依赖冲突错误:pip的依赖解析器目前没有考虑所有已安装的包。这种行为是下列依赖冲突的根源。Jupyter-console 6.4.0需要prompt-toolkit!=3.0.0,!=3.0.1,❤️.1.0,>=2.0.0,但您有不兼容的prompt-toolkit 1.0.185.0.2 更换 Jupyter-console 版本卸载Jupyter-consolepip3 uninstall jupyter-console pip3 install jupyter-console==4.0.25.1 安装requirements.txt 依赖pip install -r requirements.txt -i https://pypi.douban.com/simple #如果提示albumentations包版本不存在则将requirements.txt中的albumentations包版本替换成 #albumentations==1.3.16. 下载轻量的推理模型安装服务模块前,需要准备推理模型并放到正确路径。我们将使用的是最新PP-OCRv3模型,默认模型路径为:**检测模型:./inference/ch_PP-OCRv3_det_infer/识别模型:./inference/ch_PP-OCRv3_rec_infer/方向分类器:./inference/ch_ppocr_mobile_v2.0_cls_infer/进入/home/PaddleOCR/deploy/hubserving/ocr_system下cd /home/PaddleOCR/deploy/hubserving/ocr_system # 下载并解压检测模型 wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar && tar -xf ch_PP-OCRv3_det_infer.tar && rm -rf ch_PP-OCRv3_det_infer.tar # 下载并解压识别模型 wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar && tar -xf ch_PP-OCRv3_rec_infer.tar && rm -rf ch_PP-OCRv3_rec_infer.tar # 下载并解压方向分类器 wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar -xf ch_ppocr_mobile_v2.0_cls_infer.tar && rm -rf ch_ppocr_mobile_v2.0_cls_infer.tar全部下载解压完后输ls查看目录确认6.1 修改模型路径修改三个dir,注意要绝对路径,以及rec_imgage_shape最新PP-OCR3为3.48.3206.2 单张图片识别测试回到 cd /home/paddleOCR 目录下图片测试用官方自带的图片来测试识别,官方自带图片目录为 /home/PaddleOCR/doc/imgspython3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system/ch_PP-OCRv3_det_infer/" --rec_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system//ch_PP-OCRv3_rec_infer/" --cls_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls true --use_gpu false7. PaddleHub Server 服务部署这种部署形式也是官方推荐的部署方式之一。7.1 安装服务模块PaddleOCR提供3种服务模块,根据需要安装所需模块安装检测+识别串联服务模块即可 cd /home/PaddleOCR 安装检测服务模块: hub install deploy/hubserving/ocr_det/ 或,安装分类服务模块: hub install deploy/hubserving/ocr_cls/ 或,安装识别服务模块: hub install deploy/hubserving/ocr_rec/ 或,安装检测+识别串联服务模块: hub install deploy/hubserving/ocr_system/7.2 自定义修改服务模块(后续,现可跳过)如果需要修改服务逻辑,你一般需要操作以下步骤(以修改ocr_system为例):7.2.1 停止服务hub serving stop --port/-p XXXX7.2.2 修改参数到相应的module.py和params.py等文件中根据实际需求修改代码。例如,如果需要替换部署服务所用模型,则需要到 params.py 中修改模型路径参数det_model_dir和rec_model_dir,如果需要关闭文本方向分类器,则将参数use_angle_cls置为False,当然,同时可能还需要修改其他相关参数,请根据实际情况修改调试。 强烈建议修改后先直接运行module.py调试,能正确运行预测后再启动服务测试。7.2.3 卸载旧服务包hub uninstall ocr_system7.2.4 安装修改后的新服务包hub install deploy/hubserving/ocr_system/7.2.5 重新启动服务hub serving start -m ocr_system7.3 hub 配置文件init_args中的可配参数与module.py中的_initialize函数接口一致。其中,当use_gpu为true时,表示使用GPU启动服务。predict_args中的可配参数与module.py中的predict函数接口一致。注意:使用配置文件启动服务时,其他参数会被忽略。如果使用GPU预测(即,use_gpu置为true),则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,如:export CUDA_VISIBLE_DEVICES=0,否则不用设置。use_gpu不可与use_multiprocess同时为true7.4 启动 hub 服务命令hub serving start -c config.json成功会出现以下说明,后续测试记得将8868端口放开8. 部署 web 服务程序8.1 安装flask,flask-cors下面使用flask 部署web框架cd /home/PaddleOCR/tools pip3 install flask安装flask-corspip3 install flask-cors8.2 新建web服务程序在 /home/PaddleOCR/tools 目录下新建一个新的py文件,文件名为testmyocr.py 并且给权限为 775testmyocr.py的内容如下:# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. import os import sys __dir__ = os.path.dirname(os.path.abspath(__file__)) sys.path.append(__dir__) sys.path.append(os.path.abspath(os.path.join(__dir__, '..'))) from ppocr.utils.logging import get_logger logger = get_logger() import cv2 import numpy as np import time from PIL import Image from ppocr.utils.utility import get_image_file_list from tools.infer.utility import draw_ocr, draw_boxes import requests import json import base64 from flask import Flask,request from flask_cors import CORS import requests app = Flask(__name__) CORS(app) # 解决跨域问题 def cv2_to_base64(image): return base64.b64encode(image).decode('utf8') def draw_server_result(image_file, res): img = cv2.imread(image_file) image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) if len(res) == 0: return np.array(image) keys = res[0].keys() if 'text_region' not in keys: # for ocr_rec, draw function is invalid logger.info("draw function is invalid for ocr_rec!") return None elif 'text' not in keys: # for ocr_det logger.info("draw text boxes only!") boxes = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) boxes = np.array(boxes) draw_img = draw_boxes(image, boxes) return draw_img else: # for ocr_system logger.info("draw boxes and texts!") boxes = [] texts = [] scores = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) texts.append(res[dno]['text']) scores.append(res[dno]['confidence']) boxes = np.array(boxes) scores = np.array(scores) draw_img = draw_ocr( image, boxes, texts, scores, draw_txt=True, drop_score=0.5) return draw_img @app.route("/test") def test(): return 'Hello World!' @app.route("/myocr", methods=["POST"] ) def myocr(): # 输入参数 image_file = request.files['file'] basepath = os.path.dirname(__file__) logger.info("{} basepath".format(basepath)) savepath = os.path.join(basepath, image_file.filename) image_file.save(savepath) img = open(savepath, 'rb').read() if img is None: logger.info("error in loading image:{}".format(image_file)) # 转为 base64 data = {'images': [cv2_to_base64(img)]} # 发送请求 url = "http://127.0.0.1:8868/predict/ocr_system" headers = {"Content-type": "application/json"} r = requests.post(url=url, headers=headers, data=json.dumps(data)) # 返回结果 res = r.json()["results"][0] logger.info(res) return json.dumps(res) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000) 8.3 启动web服务cd /home/PaddleOCR/tools 目录切换到tools下 python3 testmyocr.py & 启动web服务,启动成功会出现如下说明9. Postman工具调用测试**使用postman向 5000端口去发起请求,可以看到服务正常返回识别的结果其他方式:https://github.com/velviagris/PaddleOCRFastAPI/blob/master/README_CN.md
PaddleOCR Linux-Centos7.6安装与部署 1. 运行环境准备本人环境为阿里云服务器centos 7.6(全新镜像系统)从0开始部署PaddleOCR1.1 参考资料PaddleOCR 运行环境准备 PaddleOCR 快速开始 手把手0基础Centos下安装与部署paddleOcr 教程 PaddleOCR基于PaddleHub Serving的服务部署(docker环境) 新手Docker安装PaddleOCR快速指导(非长期有效具体看更新时间) (ziyoukaifa.com) PaddleOCR Linux-Centos7.6安装与部署1.2 PaddleOCR的环境推荐环境:PaddlePaddle >= 2.1.2 Python 3.7 CUDA10.1 / CUDA10.2 CUDNN 7.62. centos下准备好docker工具可以自己选择一个稳定的版本安装,或者不指定版本,直接安装最新版本2.1 备份之前的yum源文件cd /etc/yum.repos.d/ mv CentOS-Base.repo CentOS-Base.repo_bak2.2 更换yum源为阿里云wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo2.3 清除缓存并生成新的缓存yum.repos.d]# yum clean all yum makecache2.4测试发现还是报错yum list docker-ce --showduplicates | sort -r Error: No matching Packages to list \* updates: mirrors.bfsu.edu.cn Loading mirror speeds from cached hostfile Loaded plugins: fastestmirror, langpacks \* extras: mirrors.bfsu.edu.cn \* base: mirrors.bfsu.edu.cn2.5 添加仓库yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo2.6 IF ERROR: yum-config-manager: command not foundyum -y install yum-utils yum clean all yum makecache2.7 再次测试,发现OKyum list docker-ce --showduplicates | sort -r //显示如下 docker-ce.x86\_64 3:20.10.0-3.el7 docker-ce-stable2.8 yum install docker-ce接下来就是yum来安装docker完成yum install docker-ce2.9 启动docker服务service docker start2.10 查看docker版本,检查docker是否安装成功docker --version #显示如下 Docker version 24.0.2, build cb74dfc2.11 配置docker服务开机自启动systemctl enable docker3.Docker环境配置切换到工作目录下mkdir /home/Projects cd /home/Projects首次运行需创建一个docker容器,再次运行时不需要运行当前命令创建一个名字为ppocr的docker容器,并将当前目录映射到容器的/paddle目录下3.1镜像下载接下来docker就会自动开始下载镜像了,然后就是漫长的下载等待,大概下载时间会有10分钟左右在CPU环境下使用docker,使用docker而不是nvidia-docker创建dockersudo docker run --name ppocr -v \$PWD:/paddle --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash下载完毕后,会自动进入到镜像内部的shell里,进入下面这样的界面中。我们先直接输入exit退出 exit3.2查看docker中的运行进程docker ps3.3启动ppocr这个容器docker start ppocr3.4进入ppocr容器sudo docker container exec -it ppocr /bin/bash3.5 检查docker内的python3以及pip3版本python>=3.7.04.安装最新PaddlePaddle(2.4.2)python3 -m pip install paddlepaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple4.1 安装PaddleOCR whl包pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本这个包一般下载得会比较久4.2 包版本依赖不兼容报错问题Paddlepaddle 2.4.2需要protobuf<=3.20.0,>=3.1.0,但你有protobuf 4.23.2,这是不兼容的。4.2.1 重新换一个 protobuf 版本/home pip uninstall protobuf /home pip install protobuf==3.20.0OK没有其它包不兼容了,如果还存在包兼容问题根据错误提示升级或降级对应包即可4.3 clone PaddleOCR仓库代码cd /home git clone https://github.com/PaddlePaddle/PaddleOC #【推荐】 #如果无法访问github 的小伙伴们也可以通过gitee仓库里面将源码下载下来: git clone https://gitee.com/paddlepaddle/PaddleOCR5. 安装paddlehub(2.2.0)cd /home/PaddleOCR安装paddlehubpip3 install paddlehub==2.2.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple5.0.1 jupyter-console 包依赖冲突错误:pip的依赖解析器目前没有考虑所有已安装的包。这种行为是下列依赖冲突的根源。Jupyter-console 6.4.0需要prompt-toolkit!=3.0.0,!=3.0.1,❤️.1.0,>=2.0.0,但您有不兼容的prompt-toolkit 1.0.185.0.2 更换 Jupyter-console 版本卸载Jupyter-consolepip3 uninstall jupyter-console pip3 install jupyter-console==4.0.25.1 安装requirements.txt 依赖pip install -r requirements.txt -i https://pypi.douban.com/simple #如果提示albumentations包版本不存在则将requirements.txt中的albumentations包版本替换成 #albumentations==1.3.16. 下载轻量的推理模型安装服务模块前,需要准备推理模型并放到正确路径。我们将使用的是最新PP-OCRv3模型,默认模型路径为:**检测模型:./inference/ch_PP-OCRv3_det_infer/识别模型:./inference/ch_PP-OCRv3_rec_infer/方向分类器:./inference/ch_ppocr_mobile_v2.0_cls_infer/进入/home/PaddleOCR/deploy/hubserving/ocr_system下cd /home/PaddleOCR/deploy/hubserving/ocr_system # 下载并解压检测模型 wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar && tar -xf ch_PP-OCRv3_det_infer.tar && rm -rf ch_PP-OCRv3_det_infer.tar # 下载并解压识别模型 wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar && tar -xf ch_PP-OCRv3_rec_infer.tar && rm -rf ch_PP-OCRv3_rec_infer.tar # 下载并解压方向分类器 wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar -xf ch_ppocr_mobile_v2.0_cls_infer.tar && rm -rf ch_ppocr_mobile_v2.0_cls_infer.tar全部下载解压完后输ls查看目录确认6.1 修改模型路径修改三个dir,注意要绝对路径,以及rec_imgage_shape最新PP-OCR3为3.48.3206.2 单张图片识别测试回到 cd /home/paddleOCR 目录下图片测试用官方自带的图片来测试识别,官方自带图片目录为 /home/PaddleOCR/doc/imgspython3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system/ch_PP-OCRv3_det_infer/" --rec_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system//ch_PP-OCRv3_rec_infer/" --cls_model_dir="/home/PaddleOCR/deploy/hubserving/ocr_system/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls true --use_gpu false7. PaddleHub Server 服务部署这种部署形式也是官方推荐的部署方式之一。7.1 安装服务模块PaddleOCR提供3种服务模块,根据需要安装所需模块安装检测+识别串联服务模块即可 cd /home/PaddleOCR 安装检测服务模块: hub install deploy/hubserving/ocr_det/ 或,安装分类服务模块: hub install deploy/hubserving/ocr_cls/ 或,安装识别服务模块: hub install deploy/hubserving/ocr_rec/ 或,安装检测+识别串联服务模块: hub install deploy/hubserving/ocr_system/7.2 自定义修改服务模块(后续,现可跳过)如果需要修改服务逻辑,你一般需要操作以下步骤(以修改ocr_system为例):7.2.1 停止服务hub serving stop --port/-p XXXX7.2.2 修改参数到相应的module.py和params.py等文件中根据实际需求修改代码。例如,如果需要替换部署服务所用模型,则需要到 params.py 中修改模型路径参数det_model_dir和rec_model_dir,如果需要关闭文本方向分类器,则将参数use_angle_cls置为False,当然,同时可能还需要修改其他相关参数,请根据实际情况修改调试。 强烈建议修改后先直接运行module.py调试,能正确运行预测后再启动服务测试。7.2.3 卸载旧服务包hub uninstall ocr_system7.2.4 安装修改后的新服务包hub install deploy/hubserving/ocr_system/7.2.5 重新启动服务hub serving start -m ocr_system7.3 hub 配置文件init_args中的可配参数与module.py中的_initialize函数接口一致。其中,当use_gpu为true时,表示使用GPU启动服务。predict_args中的可配参数与module.py中的predict函数接口一致。注意:使用配置文件启动服务时,其他参数会被忽略。如果使用GPU预测(即,use_gpu置为true),则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,如:export CUDA_VISIBLE_DEVICES=0,否则不用设置。use_gpu不可与use_multiprocess同时为true7.4 启动 hub 服务命令hub serving start -c config.json成功会出现以下说明,后续测试记得将8868端口放开8. 部署 web 服务程序8.1 安装flask,flask-cors下面使用flask 部署web框架cd /home/PaddleOCR/tools pip3 install flask安装flask-corspip3 install flask-cors8.2 新建web服务程序在 /home/PaddleOCR/tools 目录下新建一个新的py文件,文件名为testmyocr.py 并且给权限为 775testmyocr.py的内容如下:# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. import os import sys __dir__ = os.path.dirname(os.path.abspath(__file__)) sys.path.append(__dir__) sys.path.append(os.path.abspath(os.path.join(__dir__, '..'))) from ppocr.utils.logging import get_logger logger = get_logger() import cv2 import numpy as np import time from PIL import Image from ppocr.utils.utility import get_image_file_list from tools.infer.utility import draw_ocr, draw_boxes import requests import json import base64 from flask import Flask,request from flask_cors import CORS import requests app = Flask(__name__) CORS(app) # 解决跨域问题 def cv2_to_base64(image): return base64.b64encode(image).decode('utf8') def draw_server_result(image_file, res): img = cv2.imread(image_file) image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) if len(res) == 0: return np.array(image) keys = res[0].keys() if 'text_region' not in keys: # for ocr_rec, draw function is invalid logger.info("draw function is invalid for ocr_rec!") return None elif 'text' not in keys: # for ocr_det logger.info("draw text boxes only!") boxes = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) boxes = np.array(boxes) draw_img = draw_boxes(image, boxes) return draw_img else: # for ocr_system logger.info("draw boxes and texts!") boxes = [] texts = [] scores = [] for dno in range(len(res)): boxes.append(res[dno]['text_region']) texts.append(res[dno]['text']) scores.append(res[dno]['confidence']) boxes = np.array(boxes) scores = np.array(scores) draw_img = draw_ocr( image, boxes, texts, scores, draw_txt=True, drop_score=0.5) return draw_img @app.route("/test") def test(): return 'Hello World!' @app.route("/myocr", methods=["POST"] ) def myocr(): # 输入参数 image_file = request.files['file'] basepath = os.path.dirname(__file__) logger.info("{} basepath".format(basepath)) savepath = os.path.join(basepath, image_file.filename) image_file.save(savepath) img = open(savepath, 'rb').read() if img is None: logger.info("error in loading image:{}".format(image_file)) # 转为 base64 data = {'images': [cv2_to_base64(img)]} # 发送请求 url = "http://127.0.0.1:8868/predict/ocr_system" headers = {"Content-type": "application/json"} r = requests.post(url=url, headers=headers, data=json.dumps(data)) # 返回结果 res = r.json()["results"][0] logger.info(res) return json.dumps(res) if __name__ == '__main__': app.run(host='0.0.0.0', port=5000) 8.3 启动web服务cd /home/PaddleOCR/tools 目录切换到tools下 python3 testmyocr.py & 启动web服务,启动成功会出现如下说明9. Postman工具调用测试**使用postman向 5000端口去发起请求,可以看到服务正常返回识别的结果其他方式:https://github.com/velviagris/PaddleOCRFastAPI/blob/master/README_CN.md -
anaconda中SSL错误:Can‘t connect to HTTPS URL because the SSL module is not available 解决方案原文地址 https://github.com/conda/conda/issues/8273大意是:conda找错了openssl的地址,conda在AnacondaDLLs目录下寻找openssl的dll文件,但实际上需要的dll在Anaconda3librarybin目录下。因此只需要将这两个文件复制到 AnacondaDLLs下即可。根据提示复制两个dll到指定目录。D:AnacondaLibrarybin -> D:AnacondaDLLs
-
修改pip install默认安装路径的方法 修改pip install默认安装路径python 模块默认安装路径在C盘,容易造成C盘占满,所以需要修改安装路径查看pip 默认安装位置cmd 输入 python -m site修改pip 默认安装位置cmd 输入 python -m site -help修改site.py内容,如下USER_SITE = "你的其他目录\lib\site-packages" USER_BASE = "你的其他目录\Scripts"增加pip配置文件pip.ini在user目录(一般是C:用户你的系统用户名)下新建pip文件夹,里面新建pip.ini文件,内容如下[global] index-url=https://mirrors.aliyun.com/pypi/simple/ target=D:/Cache/Python/Python38/site-packages修改完后就可以了,测试一下,cmd输入命令 pip install numpy至此pip安装的模块默认路径就修改了pip 安装慢,请使用国内的镜像源pip install mlxtend -i https://pypi.tuna.tsinghua.edu.cn/simple
-
python 优秀的语法糖及需要记录备忘的内容(持续更新...) python3 入门知识(难点、语法糖、备忘)内容循环中的else一、while...else...1. 格式while 条件: # 条件满足时执行的代码... else: # 如果上述的while循环没有调用break,就执行的代码...说明:只要while循环体中没有执行break,那么当while循环体中所有的代码执行完后,else中的代码也会执行如果while循环中有break那么表示整个while介绍,else中的代码也不会被执行2. 示例有break时i = 1 while i <= 3: print("哈哈,我是超神,double kill......") if i == 1: print("调用了break") break i += 1 else: print("我是else中的代码")运行结果哈哈,我是超神,double kill...... 调用了break没有break时i = 1 while i <= 3: print("哈哈,我是超神,double kill......") i += 1 else: print("我是else中的代码")运行结果哈哈,我是超神,double kill...... 哈哈,我是超神,double kill...... 哈哈,我是超神,double kill...... 我是else中的代码3. 案例i = 3 while i > 0: password = input("请输入密码:(还剩%d次机会)" % i) if password == "123456": print("密码输入正确") break i -= 1 else: print("密码输入3次全部错误,请明日再试")三、for...else...1. 格式for 变量 in 可迭代对对象: # 正常执行的代码 else: # for未使用break时执行的代码2. 示例未使用breakfor i in range(5): print("i=%d" % i) else: print("我是else中的代码...")运行结果:i=0 i=1 i=2 i=3 i=4 我是else中的代码....使用breakfor i in range(5): print("i=%d" % i) if i == 1: print("我是break哦...") break else: print("我是else中的代码...")运行结果:i=0 i=1 我是break哦...3. 案例for i in range(3, 0, -1): password = input("请输入密码:(还剩%d次机会)" % i) if password == "123456": print("密码输入正确") break else: print("密码输入3次全部错误,请明日再试")字符串切片一、是什么较为官方的说法:切片是指对操作的对象截取其中一部分的操作通俗来说:一种能够从数据中取到一部分数据的方式例如,有一个字符串"abcdef",我们可以通过切片取到"cde"切片不仅可以在字符串中应用,还可以对列表、元组等进行操作,简言之“切片”功能很重要。本节课我们以字符串为例讲解“切片”二、怎样用1. 语法[起始:结束:步长]注意选取的区间从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身),步长表示选取间隔默认“步长”为1,即取完一个下标的数据之后,第二个下标的是在刚刚下标基础上+1步长为正数,表示从左向右取数据步长为负数,表示从右向左取数据2. 示例demo1name = 'abcdef' print(name[0:3]) # 取下标为0、1、2的字符,注意取不到下标为3的空间 运行结果:abc推导式一、是什么推导式:就是一种能够快速生成数据的方式例如,想要快速生成由1~20内所有奇数数组成的列表,就可以用"推导式",代码如下[x for x in range(1, 21) if x % 2 == 0]运行结果如下:[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]二、分类推导式,根据最终要生成的数据,简单划分为列表推导式集合推导式字典推导式注意:没有元组推导式,而是生成器(在Python高级进阶课程中在学习)三、列表推导式列表推导式:一种可以快速生成列表的方式1. 格式[变量 for 变量 in 可迭代对象]四、集合推导式集合推导式:一种快速生成集合的方式示例:In [5]: a = {x for x in range(1, 21) if x % 2 == 0} In [6]: type(a) Out[6]: set In [7]: a Out[7]: {2, 4, 6, 8, 10, 12, 14, 16, 18, 20}集合推导式中也可以用if等,与列表推导式在格式上很类似,这里就不做过多的介绍,请类别列表推导式进行学习五、字典推导式字典推导式:一种快速生成字典的方式示例1:快速生成一个1~10内key为某个数此时value为平方的字典{x:x**2 for x in range(1, 11)}拆包一、是什么拆包:是一种快速提取数据的方式例如,有一个元组(11, 22, 33, 44)想快速的提取每个元素且赋值给num1, num2, num3, num4这4个变量普通的做法,较为繁琐nums = (11, 22, 33, 44) # 定义一个元组 num1 = nums[0] # 通过下标来提取 num2 = nums[1] # 通过下标来提取 num3 = nums[2] # 通过下标来提取 num4 = nums[3] # 通过下标来提取拆包的方式,可以见非常简洁num1, num2, num3, num4 = (11, 22, 33, 44) # 一行代码搞定二、拆列表示例a, b = [11, 22] print(a) print(b) 运行结果:11 22三、拆元组示例a, b = (11, 22) print(a) print(b) 运行结果:11 22四、拆集合示例a, b = {11, 22} print(a) print(b) 运行结果:11 22五、拆字典1. 一般用法示例a, b = {"name": "王老师", "web_site": "http://www.codetutor.top"} print(a) print(b) 运行结果:name web_site默认取到的是字典的key,而不是value六、注意点=右边要拆的数据元素的个数 要 与=左边存的变量个数相同错误示例如下:a, b = [11, 22, 33]函数参数高级用法一、缺省参数1. 是什么缺省参数也叫做默认参数,是指定义函数时形参变量有默认值,如果调用函数时没有传递参数,那么函数就用默认值,如果传递了参数就用传递的那个数据2. 做什么当调用函数时,有些参数不必传递,而是用默认值,这样的场景往往都用缺省参数例如,一个学校现在开始检查每个学生的信息,学生说:报告老师我是xxx学校xxx系xxx年级xxx班学生,名字叫xxxx,大家想只要是这学校的学生那么“xxx学校”就可以省略不用说了,因为大家都知道。所以就可以认为默认的学校就是xxx,而当其他学校的学生介绍时yyy学校名字案例说就一定要说清楚,否则让人弄混了来个demo试试看def print_info(name, class_name, grade, department_name, school_name="通俗易懂"): print("老师好:我是来自 %s学校 %s系 %s年级 %s班级 的学生,我叫%s" % ( school_name, department_name, grade, class_name, name )) print_info("dong", "超牛", "二", "软件工程") print_info("dong", "超牛", "二", "软件工程", "codetutor.top") 运行结果老师好:我是来自 通俗易懂学校 软件工程系 二年级 超牛班级 的学生,我叫dong 老师好:我是来自 codetutor.top学校 软件工程系 二年级 超牛班级 的学生,我叫dong3. 注意点缺省参数只能在形参的最后(即最后侧)缺省参数全挨在一起(在右侧),不是缺省参数挨在一起(在左侧)>>> def printinfo(name, age=35, sex): ... print name ... File "<stdin>", line 1 SyntaxError: non-default argument follows default argument二、命名参数1. 是什么命名参数是指:在调用函数时,传递的实参带有名字,这样的参数叫做命名参数2. 做什么命名参数能够在调用函数的时候,不受位置的影响,可以给需要的参数指定传递数据3. 注意点命名参数的名字要与形参中的名字相同,不能出现命名参数名字叫做num,而形参中没有变量num如果形参左侧有普通的形参,调用函数时传递的参数一定要先满足这些形参,然后再根据需要编写命名参数def test(a, b, c=100, d=200): print("a=%d, b=%d, c=%d, d=%d" % (a, b, c, d)) # 下面的方式都成功 test(11, 22) test(11, 22, 33) test(11, 22, 33, 44) test(11, 22, d=33, c=44) # 下面的方式都失败 test(c=1, d=2) # 缺少a、b的值 test(c=1, d=2, 11, 22) # 11, 22应该在左侧三、不定长参数1. 是什么不定长参数:定义函数的时候形参可以不确定到底多少个,这样的参数就叫做不定长参数不定长参数有2种方式表示*args :表示调用函数时多余的未命名参数都会以元组的方式存储到args中**kwargs:表示调用函数时多余的命名参数都会以键值对的方式存储到kwargs中注意:*和**是必须要写的,否则就变成了普通的形参了当我们说不定长参数的时候,就是指*args和**kwargs2. 做什么通过不定长参数,能够实现调用函数时传递实参个数可以随意变换的需求例如def test(a, b, *args, **kwargs): print("-------------------------------") print(a, type(a)) print(b, type(b)) print(args, type(args)) print(kwargs, type(args)) test(11, 22) test(11, 22, 33, 44, 55, 66) test(11, 22, 33, 44, 55, 66, name="wanglaoshi", web_site="http://www.codetutor.top") 运行结果:------------------------------- 11 <class 'int'> 22 <class 'int'> () <class 'tuple'> {} <class 'tuple'> ------------------------------- 11 <class 'int'> 22 <class 'int'> (33, 44, 55, 66) <class 'tuple'> {} <class 'tuple'> ------------------------------- 11 <class 'int'> 22 <class 'int'> (33, 44, 55, 66) <class 'tuple'> {'name': 'wanglaoshi', 'web_site': 'http://www.codetutor.top'} <class 'tuple'>3. 注意点加了星号*的变量args会存放所有未命名的变量参数,args为元组而加**的变量kwargs会存放命名参数,即形如key=value的参数, kwargs为字典一般情况下*args、**kwargs会在形参的最右侧args与kwargs的名字可以变,例如叫*aa,**bb都是可以,但一般为了能够让其他的开发者快速读懂我们的代码最好还是不改4. 特殊情况缺省参数在*args后面def sum_nums_3(a, *args, b=22, c=33, **kwargs): print(a) print(b) print(c) print(args) print(kwargs) sum_nums_3(100, 200, 300, 400, 500, 600, 700, b=1, c=2, mm=800, nn=900) 说明:*args后可以有缺省参数,想要给这些缺省参数在调用时传递参数,需要用命名参数传递,否则多余的未命名参数都会给args如果有**kwargs的话,**kwargs必须是最后的通过*、**拆包一、引入假如有函数def test(a, b, c): print(a + b + c) 现在自己拥有的数据nums = [11, 22, 33]怎样养才能在调用test函数的时候,将nums给传递过去呢?def test(a, b, c): print(a + b + c) nums = [11, 22, 33] test(nums[0], nums[1], nums[2]) 上述代码用的方式虽然能行,但不是很简洁为了能够用更加简洁的方式实现上述场景需求,Python可以通过*、**将数据拆包后传递二、使用*拆包有时在调用函数时,这个函数需要的是多个参数,而自己拥有的是一个列表或者集合这样的数据,此时就用可以用*拆包使用方式*列表 *元组 *集合用*拆包的方式实现上述功能def test(a, b, c): print(a + b + c) nums = [11, 22, 33] test(*nums) # 此时的*的作用就是拆包,此时*nums相当于11, 22, 33 即test(11, 22, 33) 当是元组时依然可以拆def test(a, b, c): print(a + b + c) nums = (11, 22, 33) test(*nums) 当时集合是也是可以拆的def test(a, b, c): print(a + b + c) nums = {11, 22, 33} test(*nums) 注意:*对列表、元组、集合可以拆包,但一般都是在调用函数时用三、使用**拆包使用**可以对字典进行拆包,拆包的结果是命名参数例如def test(name, web_site, age): print(name) print(web_site) print(age) info = { "name": "王老师", "web_site": "www.codetutor.top", "age": 18 } test(**info) 四、难点1. 疑惑点学习不定长参数时,掌握了*args、**kwargs现在学习拆包时,也用到了*、**那它们之间有什么关系呢?答:没有任何关系,只是长得像罢了2. 示例def test1(*args, **kwargs): print("----在test1函数中----") print("args:", args) print("kwargs", kwargs) def test2(*args, **kwargs): print("----在test2函数中----") print("args:", args) print("kwargs", kwargs) test1(args, kwargs) test2(11, 22, 33, name="王老师", age=18) 运行结果----在test2函数中---- args: (11, 22, 33) kwargs {'name': '王老师', 'age': 18} ----在test1函数中---- args: ((11, 22, 33), {'name': '王老师', 'age': 18}) kwargs {}3. 示例2def test1(*args, **kwargs): print("----在test1函数中----") print("args:", args) print("kwargs", kwargs) def test2(*args, **kwargs): print("----在test2函数中----") print("args:", args) print("kwargs", kwargs) test1(*args, **kwargs) test2(11, 22, 33, name="王老师", age=18) 运行结果----在test2函数中---- args: (11, 22, 33) kwargs {'name': '王老师', 'age': 18} ----在test1函数中---- args: (11, 22, 33) kwargs {'name': '王老师', 'age': 18}匿名函数一、是什么匿名函数:没有名字的函数,在Python中用lambda定义示例lambda x, y: x + y # 定义了一个匿名函数 1.没有名字 2.完成2个数的加法操作二、做什么可以用一行代码完成简单的函数定义可以当做实参快速传递到函数中去三、怎样用用lambda关键词能匿名函数。这种函数得名于省略了用def声明函数的标准步骤1. 格式lambda函数的语法只包含一个语句,如下:lambda 形参1, 形参2, 形参3: 表达式2. 注意lambda函数能接收任何数量的参数但只能返回一个表达式的值,其默认就是返回的,不用写return3. 使用方式既然我们已经知道def定义函数时的变量存储的是函数的引用,所以只要有了这个函数的引用,也就可以通过变量名()的方式调用函数而,函数分为def定义的普通函数,和用lambda定义的匿名函数,所以无论一个变量例如b保存的是普通函数的引用,还是匿名函数的引用,都可以用b()方式调用b指向的函数一般情况下对匿名函数的使用有2种方式通过lambda定义匿名函数,然后用一个变量指向这个匿名函数,然后通过变量名()调用这个匿名函数直接在调用其它函数实参的位置通过lambda定义匿名函数,会将这个匿名函数的引用当做实参进行传递方式1示例:# 定义了一个匿名函数,然后让变量add_2_nums指向它 add_2_nums = lambda x, y: x + y # 调用add_2_nums指向的匿名函数 print("10+20=" % add_2_nums(10, 20)) 以上实例输出结果:0+20=30方式2示例:def fun(a, b, opt): print("a = %d" % a) print("b = %d" % b) print("result = %d" % opt(a, b)) # 此时opt指向了第7行定义的匿名函数,所以opt(a, b)就相当于调用匿名函数 fun(1, 2, lambda x, y: x + y) # 定义一个匿名函数,且将它的引用当做实参进行传递 其他语言匿名函数及Lambda:javascript、ES6新增语法“箭头函数”,例:(a,b)=>{return a+b;}C#的匿名函数,例:var func = ((Func<int, int, int>)((x, y) => { return x+y; }));引用id(a)可以查询a变量地址文章转自:https://doc.itprojects.cn/0001.zhishi/python.0001.python3kuaisurumen/index.html#/README截取部分需要备忘和语法糖部分记录
-
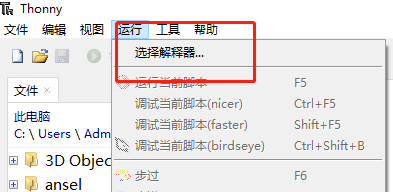
MicroPython-ESP32开发环境搭建 相关工具及文件下载IDE-thonny:https://thonny.org/MicroPython:https://micropython.org/windows-ESP32驱动及其他相关文件:https://gitee.com/panxin1213/micropythontools/环境安装首先要安装thonny,然后安装windows-ESP32驱动,再将下载的micropython对应esp32电路板的烧录进板子中。thonny安装IDE安装很简单,直接下一步下一步就可以了。ESP32,windows驱动安装下载好驱动包后安装与系统版本相关的exe文件就可以了。MicroPython烧录1、打开thonny,选择运行-选择解释器2、在弹开的窗口中,选择thonny使用的解释器,这里使用MicroPython,然后Port部分选择安装好驱动的端口,这里要链接好电路板。3、如果是新的电路板,还没有烧录过环境的时候,需要点击Install or update firmware,烧录micropython解释器进入电路板,如下图所示,烧录环境4、烧录成功后,回显示done,表示成功,如果显示 Timed out waiting for packet header等错误,需要长按住电路板上的boot键,然后再按确定重新烧录。测试运行环境弄好后如下图,可以再thonny上看到对应链接上的电路板micropython环境及电路板上的python文件。